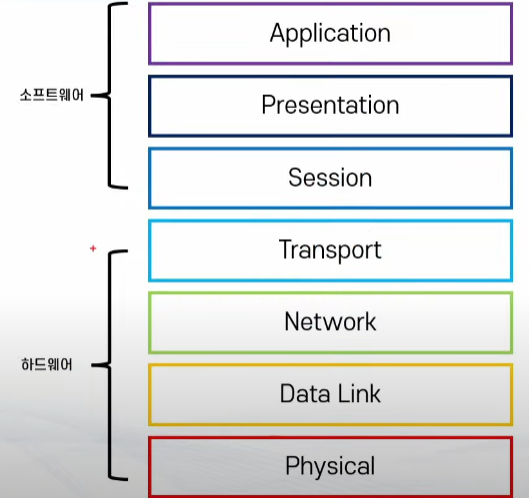
이번에는 Elasticsearch Mapping에 대해 알아보자
먼저 classes라는 인덱스를 생성해주자
curl -XPUT 'http://localhost:9200/classes'
생성 이후 GET 메서드로 조회를 해보면 아래와 같이 'mappings' 필드가 비어있는 것을 볼 수 있다.

Mapping은 데이터베이스의 스키마와 같다. 직접 매핑을 설정해주지 않아도 Elasticsearch에 저장하는 것은 무리가 없지만 추후에 Kibana를 활용해 데이터를 시각화 할 때 날짜를 문자로 인식할 수 있는 에러를 방지하기 위해 Mapping은 필수다.
Mapping 정보는 아래와 같고 미리 mapping.json 파일에 저장해두자
{
"properties": {
"title": {
"type": "text"
},
"professor": {
"type": "text"
},
"major": {
"type": "text"
},
"semester": {
"type": "text"
},
"student_count": {
"type": "integer"
},
"unit": {
"type": "integer"
},
"rating": {
"type": "integer"
},
"submit_date": {
"type": "date",
"format": "yyyy-MM-dd"
},
"school_location": {
"type": "geo_point"
}
}
}
해당 json 파일을 통해 다음 curl 요청으로 Mapping을 진행하자
curl -XPUT 'http://localhost:9200/classes/_mapping' -H "Content-Type: application/json" -d @mapping.json
Mapping 이후 classes 인덱스를 조회하면 이전과 다르게 Mapping 항목이 채워진 것을 볼 수 있다.

Mapping 이후 bulk를 사용해서 데이터를 넣어보자
curl -X POST 'http://localhost:9200/_bulk' -H "Content-Type: application/json" --data-binary @data.json
##data.json
{ "index" : { "_index" : "classes", "_id" : "1" } }
{"title" : "Machine Learning","Professor" : "Minsuk Heo","major" : "Computer Science","semester" : ["spring", "fall"],"student_count" : 100,"unit" : 3,"rating" : 5, "submit_date" : "2016-01-02", "school_location" : {"lat" : 36.00, "lon" : -120.00}}
{ "index" : { "_index" : "classes", "_id" : "2" } }
{"title" : "Network","Professor" : "Minsuk Heo","major" : "Computer Science","semester" : ["fall"],"student_count" : 50,"unit" : 3,"rating" : 4, "submit_date" : "2016-02-02", "school_location" : {"lat" : 36.00, "lon" : -120.00}}
{ "index" : { "_index" : "classes", "_id" : "3" } }
{"title" : "Operating System","Professor" : "Minsuk Heo","major" : "Computer Science","semester" : ["spring"],"student_count" : 50,"unit" : 3,"rating" : 4, "submit_date" : "2016-03-02", "school_location" : {"lat" : 36.00, "lon" : -120.00}}
{ "index" : { "_index" : "classes", "_id" : "5" } }
{"title" : "Machine Learning","Professor" : "Tim Cook","major" : "Computer Science","semester" : ["spring"],"student_count" : 40,"unit" : 3,"rating" : 2, "submit_date" : "2016-04-02", "school_location" : {"lat" : 39.00, "lon" : -112.00}}
{ "index" : { "_index" : "classes", "_id" : "6" } }
{"title" : "Network","Professor" : "Tim Cook","major" : "Computer Science","semester" : ["summer"],"student_count" : 30,"unit" : 3,"rating" : 2, "submit_date" : "2016-02-02", "school_location" : {"lat" : 36.00, "lon" : -120.00}}
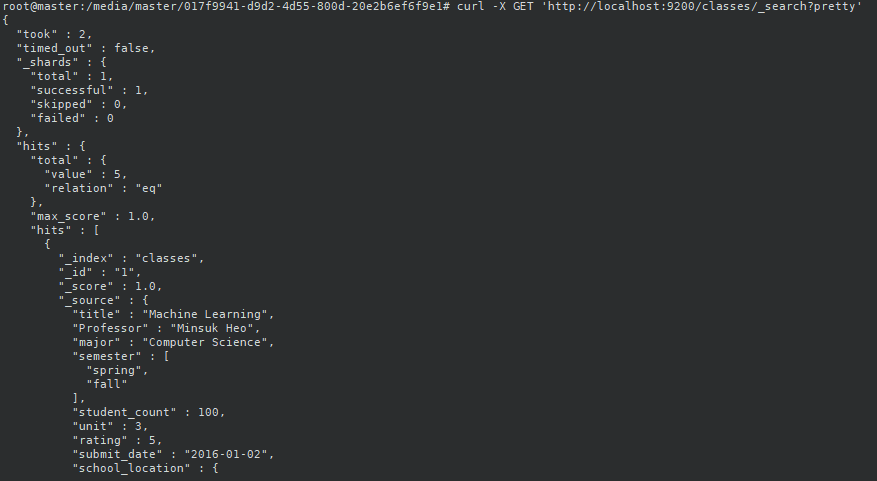
classes 인덱스를 조회해보면 다음과 같이 데이터가 잘 들어간 것을 볼 수 있다.
참고: [ELK 스택] Youtube 강의 허민석
https://www.youtube.com/watch?v=uzPTOgXe7-Q&t=274s